
Třináctka pro někoho možná není úplně nejšťastnější číslo. Ale pro Internet v Čechách, na Moravě i na Slovensku určitě šťastná byla. Protože právě ve čtvrtek 13. února roku 1992 se začala psát velmi úspěšná historie této celosvětové sítě v našich zeměpisných šířkách. Sítě, bez které bychom si dnes jen těžko představili svět, a mnozí i své vlastní fungování v něm.
Bez Internetu a jeho elektronické pošty, či různých forem chatů a konferencí, bychom nemohli komunikovat tak, jak jsme to zvyklí dělat dnes. Stejně tak by mnozí z nás nemohli pracovat na dálku, či jen získávat podklady a odevzdávat výsledky své práce po Internetu. Nemohli bychom nakupovat online, platit online, bavit se online, i třeba protestovat online, či jen vyjadřovat své názory v online diskusích. Studenti by se snad ani nemohli zapsat na zkoušku, podnikatelé by nemohli podnikat po Internetu, a řádně fungovat by nemohla ani státní správa. Kromě jiného i proto, že celý eGovernment by bez Internetu jednoduše neměl smysl.
Zkrátka a dobře: život bez Internetu by určitě možný byl, ale byl by dost odlišný od toho, na jaký jsme zvyklí dnes.
Jak jsme se připojili
Vraťme se ale zpět k počátkům: to, co se odehrálo v onen čtvrtek 13. února 1992, byl spíše symbolický a slavnostní akt. Dobová pozvánka, kterou vidíte na následujících dvou obrázcích, jej označuje jako „Oficiální zahájení provozu počítačové sítě INTERNET v ČSFR“.
Určitý formální akt byl nutný i proto, že tehdejší Internet ještě nebyl tak otevřený jako ten dnešní. Byl stále ještě „hodně akademický“, i když už začínalo jeho otevírání se komerčnímu světu. A tak i u nás se zatím připojovala pouze akademická komunita, která se musela řídit pravidly „přípustného použití“ tehdejší páteřní sítě Internetu (sítě NSFNET). Tu tehdy financovala grantová agentura NSF (National Science Foundation) – a byl to právě její představitel, pan Steven Goldstein, kdo nás onoho památného únorového dne roku 1992 jakoby „uvedl“ do celosvětového Internetu.
Mimochodem, jeho popis celé „připojovací ceremonie“ si můžete přečíst zde. Najdete v něm i zmínku o tom, že tehdejší Internet čítal na 727,000 (hostitelských) počítačů, a bylo k němu připojeno na 4500 různých sítí ve 39 zemích. Mezi ně se tedy zařadila už i ČSFR, a prakticky souběžně se k Internetu připojilo také Polsko a Maďarsko.
Jak se psala historie
Co se dělo dál, bylo popsáno již mnohokráte a velmi detailně. Proto spíše jen stručně (podrobněji např. zde): onoho 13. února 1992 se Internet „dostal“ jen na jedno místo v Praze. A tak bylo třeba jej nejprve „rozvést“ dál, po celém tehdejším Československu (přesněji už: České a Slovenské Federativní Republice). K tomu měl sloužit projekt federální sítě FESNET (Federal Educational and Scientific NETwork, návrh), který měl vybudovat páteřní síť propojující akademické instituce v celé federaci. Ale než mohl být realizován, politická realita si vyžádala jeho rozštěpení na dva samostatné projekty: český CESNET (Czech Educational and Scientific Network) a SANET (Slovak Academic Network).
Český CESNET byl slavnostně spuštěn 15. června 1993 (moje reportáž, závěrečná zpráva), a v jednotlivých lokalitách (městech s akademickou či vědeckovýzkumnou institucí) na něj navázaly metropolitní sítě, jako třeba pražský PASNET. Postupně se tak Internet dostal prakticky ke všem akademickým uživatelům. Podobně tomu bylo i na Slovensku.
Zájemci o Internet, stojící mimo akademickou sféru, ale měli ještě nějakou dobu smůlu. Samotný Internet se sice mezitím již otevřel komerčnímu využití, ale u nás doma tomu tak ještě nebylo: tehdejší Eurotel (skrze svou divizi NexTel) měl exkluzivitu na veřejné datové služby, kam spadalo i připojení k Internetu. Jenže sám takovéto služby nenabízel, a jeho exkluzivita (rozuměj: monopol) bránila tomu, aby takovéto služby (jako plně veřejné) nabízel někdo jiný.
První komerční internetoví provideři (ISP) proto mohli vzniknout až po 1. červenci 1995, ke kterému exkluzivita Eurotelu padla (kvůli prodeji jeho divize NexTel). Díky tomu pak Internet v České republice, do té doby téměř výhradně akademický, dostal mocný rozvojový impuls: ještě v roce 1995 skutečně vznikli první ryze komerční provideři. Efekt asi nejlépe dokumentuje srovnání cen za připojení v roce 1994 (tehdy jen od společností CESNET a CoNET) a koncem roku 1995 (již od celé řady komerčních ISP). Ale i tak, proti dnešním cenám, jde o „úplně jiné“ cenové relace.
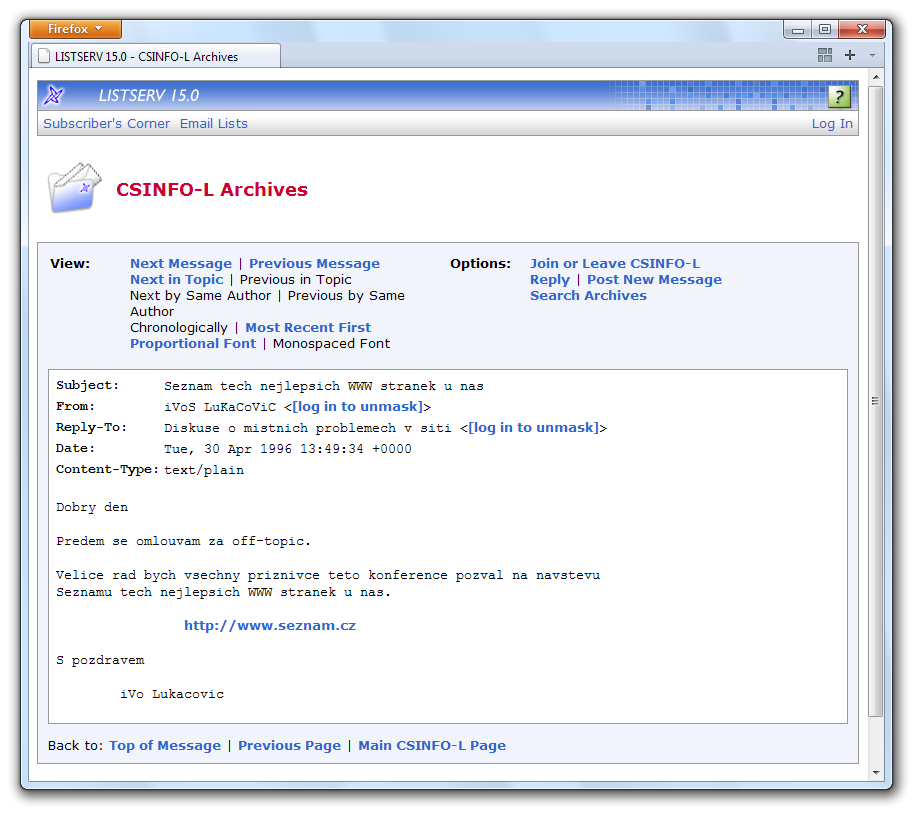
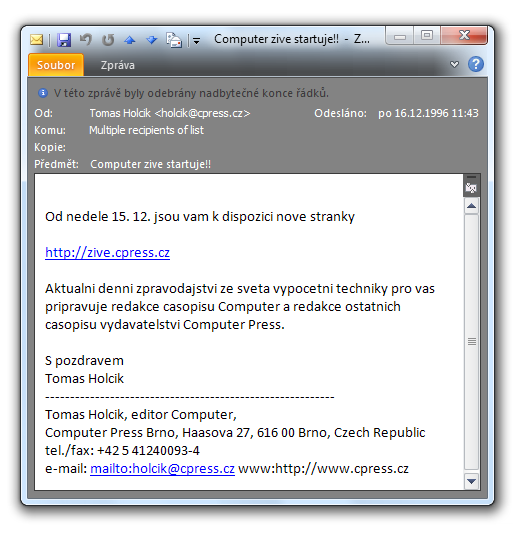
Následující rok, 1996, se již nesl ve znamení rozšiřování Internetu i mezi uživatele mimo akademickou sféru. Připomeňme si například, že 23. dubna začíná vycházet Neviditelný pes Ondřeje Neffa (jeho první čísla). Nebo že 30. dubna 1996 rozesílá Ivo Lukačovič oznámení o spuštění „Seznamu těch nejlepších WWW stránek u nás“. Ano, dnešního Seznamu. Ve stejném roce, hned na jeho počátku, odstartoval nedávno úspěšně prodaný server Jobs.cz. Koncem roku 1996 vzniklo také dnešní Živě – ale například do startu Lupy zbývaly ještě dva roky.
Jak se měnila tvář Internetu?
V tomto článku ale nechci rekapitulovat již vícekrát sepsanou historii Internetu v České republice (jako jsem to činil při desátém a patnáctém výročí). Místo toho bych se dnes chtěl pokusit o něco jiného: ukázat, a to hlavně mladší internetové generaci, jak se od dob začátků Internetu změnila jeho tvář, viděná koncovými uživateli.
Protože v první polovině devadesátých let, kdy k nám Internet přišel, skutečně „vypadal“ a používal se dosti odlišně od toho, jak vypadá a jak se používá dnes. Uvědomme si třeba, že první webové servery se v ČR objevují až počátkem roku 1994: v tzv. seznamu zdrojů CESNETu, který tehdy systematicky mapoval všechny dostupné zdroje, se první zmínka o WWW serverech (navíc prezentovaná jako novinka) objevuje až v jeho dubnovém vydání. Jednalo se přitom o pět webových serverů, z nichž čtyři byly spuštěny na pražské Karlově univerzitě, a jeden ve Fyzikálním ústavu Akademie věd. A jen pro připomenutí: úplně první (veřejně dostupný) webový server byl spuštěn v roce 1991 ve švýcarském CERNu. Jeho podobu z roku 1992 si můžete sami proklikat na této jeho archivní kopii.
Pochopitelně i webové stránky na prvních tuzemských webových serverech vypadaly úplně jinak, než jak vypadají dnes. Na následujícím videu se můžete podívat na příklady z listopadu 1994: uvidíte webové stránky pražské Matematicko-fyzikální fakulty, rektorátu Univerzity Karlovy, stránky CESNETu, ale také stránky střediska CERN či kongresové knihovny v USA.
Když ale v první polovině devadesátých let World Wide Web teprve přicházel, co se používalo místo něj? Odpověď na tuto otázku je složitější: existovala jiná služba, která se jmenovala Gopher, a která měla obdobné ambice jako World Wide Web. Tedy ambice zpřístupňovat lidem informace v jejich nejrůznější podobě. Vedle ní ale existovala velká řada úzce specializovaných služeb, které se zaměřovaly vždy jen na jednu specifickou oblast. Třeba na vyhledávání souborů v FTP archivech, či na fulltextové vyhledávání v databázích dokumentů, či na vyhledávání uživatelů a jejich kontaktních údajů. Dále pak existovala celá řada služeb, zaměřených na komunikaci mezi uživateli – ať již v reálném čase (na stejném principu, jako dnešní chat), nebo „dávkově“, jako dodnes používané emailové konference.
V praxi to znamenalo, že uživatel se musel naučit s příslušnými službami pracovat, což obvykle nebylo zdaleka tak jednoduché a intuitivní jako dnes. A hlavně musel mít na svém počítači nainstalovány klientské aplikace příslušných služeb, o které se také musel řádně starat (nastavovat je, aktualizovat atd.). Nebo mohl zkusit některou z bran mezi službami, protože tedy bylo obvyklé, že jedna služba nabízela možnost „prostupu“ do jiné služby, skrze příslušnou bránu. Takže třeba ze služby Gopher jste takto mohli „projít“ třeba do vyhledávání souborů, textů či lidí, a nepotřebovali jste na to samostatného klienta příslušné dílčí služby. Ne vždy to ale fungovalo, a pokud ano, nemuselo to nabízet zdaleka všechny možnosti, jaké skýtalo použití samotné specializované služby.
Časem ale došlo na jev, který by se dal označit jako „platformizace“: dříve zcela samostatné a úzce specializované služby časem ztratily svou vlastní identitu a zůstaly dostupné jen přes ony „brány“ z jiných služeb. Nejvíce pak z World Wide Webu, který se tak stal jakousi „platformou pro další služby“. Ty již nepotřebovaly vlastního klienta, protože se s nimi pracovalo skrze webový prohlížeč, alias browser. Stejně tak se uživatelé již nemuseli učit mnohdy specifické ovládání původních služeb. Jelikož s nimi pracovali již jen skrze webový browser, mohlo být všechno maximálně zjednodušeno a učiněno jednotným, a také velmi intuitivním: zjednodušeně řečeno uživateli stačilo ukázat prstem (tedy: kurzorem a kliknutím) na nějaké grafické znázornění toho, co si přál, aby se stalo. Na nějakou ikonku, obrázek či kus textu.
Dnes nám to možná přijde zcela banální a samozřejmé, ale ve své době – kdy se Internet otevíral masovější skupině ryze komerčních uživatelů – bylo takovéto „zjednodušení“ velmi potřebné. Protože od stále většího počtu uživatelů Internetu již nebylo možné očekávat to, co se ještě dalo očekávat od původních akademických uživatelů: že se naučí často dosti složité ovládání původních specializovaných internetových služeb. A tak tyto služby časem přišly o svou identitu a vlastně i zanikly, když se přestěhovaly „někam za“ webové servery, kde nikdo z uživatelů již nepotřebuje ani tušit o jejich existenci.
Gopher a spol.
Ukažme si nyní, jak vypadaly ony dnes již „vyhynulé“ služby Internetu.
Začít můžeme u služby Gopher, byť ani ta dnes ještě není úplně „mrtvá“. Jak ukazuje i následující obrázek (nasnímaný „živě“, včera, na mé archivní kopii starých Windows 3.11 WfWg), stále ještě existují některé servery této služby, které jsou v provozu. Spíše už ale z nostalgie, nebo jako jakési pokusy o znovuoživení Gopheru. Máte-li čím se podívat (protože podpora protokolu Gopher dnes již není standardní součástí webových browserů), zkuste třeba adresu gopher://gopher.flodgap.com (pochopitelně na původní port 70, zatímco dnešní web používá dobře známý port 80).
Na následujícím videu se pak můžete podívat na to, jak Gopher vypadal a jak fungoval v době své největší slávy. Konkrétně na podzim roku 1994. Vidět můžete nabídku tehdy existujících Gopher serverů v ČR (byly vesměs jen akademické), a podrobněji se podívat na obsah Gopher serveru tehdejšího ministerstva školství. Skrze něj pak ukázka odskakuje na Gopher server amerického CNN s ukázkou jeho zpravodajství, aby se zase vrátila zpět na aktuální informace z MŠMT, a pokračovala ukázkou „prostupu“ z Gopheru do dalších služeb. Konkrétně do vyhledávání pomocí služby WHOIS (v kontaktech lidí, kteří spravují nějakou síť připojenou k Internetu). Dále ukázka pokračuje hledáním souborů v FTP archivech, skrze bránu z Gopheru do původní tuzemské služby Nosey Parker, aby skončila (neúspěšným) pokusem o čtení síťových novin (NetNews, Usenet) skrze Gopher.
Za zmínku jistě stojí i to, že i u nás služba Gopher poněkud předběhla World Wide Web. Když se v již zmiňovaném dubnu 1994 objevuje na Seznamu zdrojů Cesnetu prvních pět WWW serverů, již tam bylo na 25 serverů služby Gopher. Poměr mezi oběma službami se vyrovnal až v průběhu roku 1994, a počátkem roku 1995 již měl WWW jednoznačně navrch.
Síťové noviny
Abyste nebylo ochuzeni o zážitek ze čtení síťových novin skrze službu Gopher, můžete se podívat na již úspěšný pokus o takovéto čtení na následujícím videu, již ale z roku 1996. V té době již prakticky nepřibývaly nové servery služby Gopher, ale ty dosavadní ještě fungovaly „naplno“.
Pro ty, kteří o síťových novinách, NetNews či Usenetu slyší poprvé, si dovolím připomenout, že se jedná o formu (kolektivní) diskuse, členěnou do diskusních skupin, které jsou distribuovány přímo k těm koncovým uživatelům, kteří si vždy musí „předplatit“ konkrétní diskusní skupiny (aby se k nim nedostával veškerý obsah všech diskusních skupin).
Dnes tato služba stále ještě „žije“. Musíme ale rozlišit její původní způsob fungování, jako samostatné služby s vlastními protokoly a vlastním způsobem šíření, přes tzv. news servery. Tato forma je dnes již „na vymření“, i když občas ještě někde nějaké news servery stále fungují (jako třeba news.felk.cvut.cz). Viz i následující „živý“ obrázek, nasnímaný včera (byť se stařičkou čtečkou trumpet Reader, která ještě nepodporuje češtinu dle MIME).
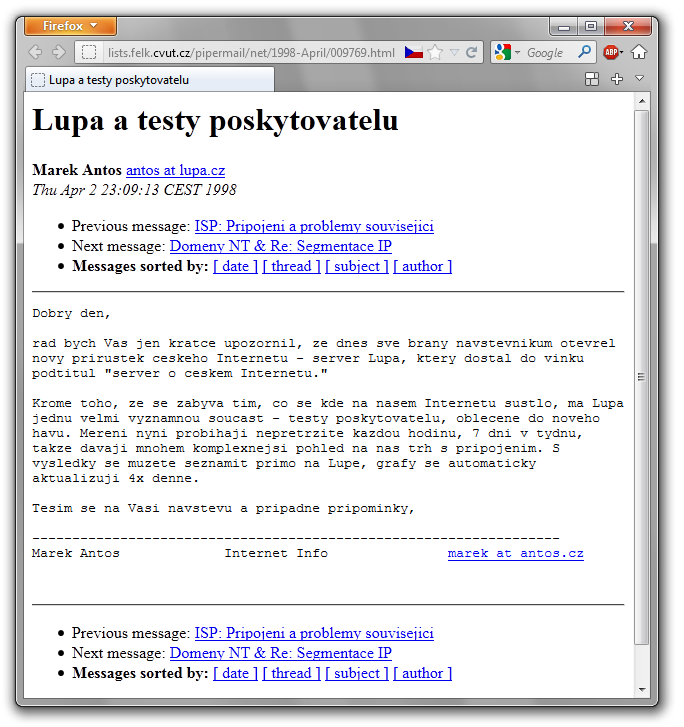
Jinak ale samotné diskuse, členěné do diskusních skupin a fungující stylem „nástěnky“ (někdo něco napíše a všichni, co sledují danou skupinu, to vidí) dnes stále ještě žijí – a to v podobě služby Groups na Google (groups.google.com). Dokládá to i srovnání předchozího a následujícího obrázku, které ukazují stejný úryvek z jedné diskusní skupiny (cz.test), poprvé skrze tradiční způsob šíření (a čtečku síťových novin, byť bez podpory češtiny), a podruhé skrze Google Groups.
S následující videoukázkou se ale můžete vrátit do roku 1996, kdy Google ještě ani neexistoval, a síťové noviny se distribuovaly skrze news servery, kterých fungovala řada i v ČR. Na ukázce vidíte i to, jak byla potřebná funkčnost („čtečky síťových novin“) zabudována do browseru Netscape Navigator.
IRC, aneb Internet Relay Chat
Jiným příkladem služby, která také časem ztratila svou původní „identitu“, ve smyslu vlastních protokolů, serverů i klientů, je služba Internet Relay Chat. Sloužila k vedení diskusí (v písemné formě) v reálném čase, a byla předchůdcem dnešních chatů, fungujících obvykle na platformě webu, případně zabudovaných do různých messengerů.
Původní Internet Relay Chat také používal členění diskusí do skupin, kterým ale neříkal „místnosti“ či nějak podobně, ale „kanály“. Uživatel se pak připojoval či odpojoval od jednotlivých kanálů, mohl poslouchat diskusi, která v nich probíhala, a také do ní přispívat. Tedy pokud na to měl vhodného klienta a věděl, na který IRC server se připojit.
Na následujících obrázcích vidíte příklad diskuse v rámci služby IRC, z 10. července 1995, a na následujícím videu živou ukázku takovéto diskuse.
Jak se kdysi hledalo
Také nejrůznější hledání bývalo dříve výrazně odlišné od toho dnešního. Dnes se nám nabízí jedna služba (např. již zmiňovaný Google), která umí vyhledávat „všechno a všude“. Dříve tomu tak nebylo, a na různé druhy vyhledávání bylo nutné použít samostatné vyhledávací služby, s vlastní logikou fungování a obvykle i s vlastním klientem.
Například služba Gopher měla vlastní vyhledávací službu, která se jmenovala Veronica a která prohledávala jeho nabídky. Takže abyste nemuseli systematicky procházet jednotlivá nabídková menu Gopheru, zeptali jste se nejprve služby Veronica (samozřejmě opět skrze Gopher), a ta už vás navedla na správnou nabídku. Příklad ukazuje následující video.
Pokud jste chtěli hledat nějaký soubor, o kterém jste věděli, že by se mohl nacházet v některém z FTP archivů, museli jste se nejprve poohlédnout po některém ze serverů služby Archie. Ty mapovaly obsah určitého počtu FTP archivů, pamatovaly si jejich obsah, a pak odpovídaly na dotazy typu „kde najdu takový a takový soubor“ (myšleno: daného jména a přípony). Pokud to Archie server věděl, odpověděl, a tazatel se pak obrátil již přímo na příslušný FTP archiv, odkud si příslušný soubor stáhl. Příklad ukazuje následující videoukázka, na které vidíte použití samostatného (lokálního) klienta služby Archie. Tomu se zadalo, co hledáte (jméno a přípona souboru), ale muselo se mu říci i to, kterému Archie serveru má být dotaz položen. Ten pak také odpověděl, pokud věděl jak.
Zajímavé je, že v České republice žádný Archie server provozován nebyl. Ani nemusel, protože jsme měli něco lepšího: vlastní službu s názvem Nosey Parker, vyvinutou na Technické univerzitě v Liberci. Údajně vyvinutou proto, že licence na Archie server byla příliš drahá, zatímco vývoj vlastní služby přišel levněji.
Nosey Parker (česky též: Čmuchal) ale neměl vlastního klienta a používal se pouze z jiných služeb, skrze příslušné brány. Ostatně, na prvním videu se službou Gopher jste mohli vidět hledání pomocí Nosey Parkera právě z prostředí Gopheru, skrze příslušnou bránu. Na následujícím videu pak můžete vidět, jak se dal Nosey Parker používat skrze World Wide Web.
Komplikovanější to bylo také s fulltextovým vyhledáváním v textových dokumentech. Dnes, když něco hledáte třeba přes Google, tak nemusíte řešit „kde“ se má hledat – protože Google, stejně jako další vyhledávače, hledá „všude“. Jenže dříve tomu tak nebylo. První vyhledávače, které byly schopné hledat uvnitř textových dokumentů konkrétní slova a slovní spojení, zvládaly jen jednotlivé databáze textových dokumentů. Takže nehledaly všude, ale jen v těch konkrétních databázích, které jste jim explicitně zadali (a které si samozřejmě dopředu „zmapovaly“, tzv. zaindexovaly).
Na tomto principu fungovala i služba WAIS (Wide Area Information Server), která byla první službou pro fulltextové vyhledávání na Internetu. Jak ukazuje i následující ukázka, využívající lokálního klienta této služby, nejprve jste museli zadat jednu nebo několik databází, ve které se mělo hledat. Teprve pak jste mohli zadat to, co vlastně hledáte – a ono se to hledalo právě a pouze ve vámi určených databázích.
Ještě další ukázka pak ukazuje stejnou službu WAIS pro plnotextové vyhledávání, ale tentokráte využívanou skrze bránu ze služby Gopher.
Telnet, aneb vzdálené přihlašování
Z dnešního pohledu jsou velmi zajímavé takové internetové služby, které se využívaly „na dálku“, prostřednictvím vzdáleného přihlašování a služby Telnet. V zásadě se jednalo o aplikace, které běžely na některém vzdáleném (hostitelském) počítači, a to ve znakovém režimu. Uživatel s nimi pracoval na dálku, když se jeho počítač přes Internet choval jako vzdálený terminál.
Příklad takto řešeného přístupu do knihovního systému na pražském ČVUT vidíte na následujícím videu.
Z dnešního pohledu by tyto služby mohly být skoro synonymem pro malou uživatelskou vstřícnost, jakou nabízely staré počítače bez grafického uživatelského rozhraní. Také s češtinou na nich bývaly velké problémy, nehledě na nutnost obvykle ručního hledání vyhovující varianty emulovaného terminálu, se kterým by si vzdálená aplikace rozuměla.
Na druhou stranu v takovéto podobě existovala velká řada aplikací, původně vyvinutých jen jako „lokální“. S nástupem Internetu se rázem staly dostupné odkudkoli „na dálku“. S tím ale současně vyvstal problém: jak se o nich potenciální zájemci dozvědí? Jak zjistí, na který počítač se mají pomocí Telnetu přihlásit, a pod jakým uživatelským jménem a heslem se mají přihlásit?
Řešení se našlo v podobě služby jménem Hytelnet: byla to vlastně jakási databáze takovýchto aplikací, spolu s nezbytnými údaji o způsobu jejich využití (jak se kde přihlásit atd.). Tato služba byla dostupná jako samostatná aplikace, vlastně jako jakýsi samostatný klient, jehož použití vidíte na následující ukázce (spolu s přihlášením do naší Národní knihovny).
Ale Hytelnet byl dostupný i skrze brány z dalších služeb, mezi kterými pochopitelně nechyběl ani World Wide Web. Na poslední ukázce vidíte takovéto vyhledání údajů pro vstup do knihovny Parlamentu ČR, a pochopitelně také její návštěvu.

Pozvánka do muzea
Pokud vás zaujaly ukázky v tomto článku, a pokud se zajímáte o historii Internetu (zejména) v ČR, dovolím si vás pozvat do malého Muzea Internetu .cz, kde najdete ještě řadu dalších věcí. Včetně videí, screenshotů, ale i různých historických dokumentů, a také zrekonstruovaných archivních kopií historických webů a článků o historii Internetu.
Najdete zde například také kompletní web o Járovi Cimrmanovi, se seznamem jeho výtvorů, který v roce 1995 vytvořil jeden tehdejší student pražského ČVUT – a který se následně znelíbil pánům Smoljakovi a Svěrákovi. To přimělo onoho studenta (jistého Iva Lukačoviče), aby ve chvílích volna začal vytvářet nějaký úplně jiný seznam. Ale to už je zase jiná historie…





{kind=link}
{kind=link}
{kind=link}