

Server Lupa.cz slaví 25. narozeniny. K výročí vám nabídneme sérii textů, podcastů a offline diskusí k dopadům AI na podobu internetu. Vše najdete na této speciální stránce.
S ChatGPT už se bavil asi každý, stejně tak i já s generativními modely experimentuji prakticky denně už řadu měsíců. A stejně dlouho vznikal tenhle článek. Slibuji jej už asi od půlky února (přečtěte si i první text Jak si pokecat (a programovat) s neuronkou ChatGPT, aby to stálo za ten čas) a konečně, po měsících, jsem jej dopsal. Ono totiž – co platilo včera, to už je dneska zastaralé, jak postupně přibývají omezení a direktivy během testování GPT modelů. Takže teď doufám, že tohle bude aktuální alespoň měsíc…
Pojďme na to. Ukážeme si známé i méně známé finty pro komunikaci s neuronkou, hlavně ale praktické příklady. Mně to šetří hodiny práce týdně, práci nechme strojům, že?
Tip číslo 0 – pokud s tím dokážete komunikovat anglicky, komunikujte s tím anglicky. S ohledem na množství textů, na kterých se to učilo, dává angličtina nejlepší možné výsledky. V češtině je to o několik řádů horší.
Temperature – kruciální parametr, o kterém se moc nedočtete
AKTUALIZACE 17:45 - Věci se opravdu mění velmi rychle. Níže uvedený tip ohledně temperature už v aktuální verzi ChatGPT nefunguje. Je ale také možné že se s dalším updatem tato možnost znovu vrátí.
Temperature, neboli teplota (nebo spíše horečka, v tomto případě), je asi nejzásadnější parametr, který můžete použít v promptech pro GPT modely. Jeho hodnota se pohybuje od 0 do 1 a určuje, jak moc náhodná (kreativní) bude odpověď na zadání.

Zjednodušeně řečeno – při hodnotě 0 bude vždy odpověď podle nejpravděpodobnějšího výpočtu, se zvyšující se hodnotou bude neuronka stále kreativnější a výstup se bude více a více lišit. A hrozí, že bude halucinovat.
Standardní hodnota temperature je u ChatGPT nastavena někde kolem 0,3–0,55, u Bing AI záleží na zvoleném režimu. No a k čemu nám to je, tahle znalost? Přes klíčová slova můžeme neuronce říci, jakou úroveň má použít. Takže pokud začneme prompt příkazem „Set temperature to 0.“, získáme zcela nekreativní výstup (to se hodí zejména u sumarizace textů nebo při programování), se zvyšováním hodnoty naopak získáme „tvůrčího ducha“.
Tohle je také jedna z mála direktiv, které nelze GPT modelu zadat v češtině (alespoň jsem nezjistil, jak by to bylo možné). (Tip: pokud nebude fungovat nastavení temperature přes „set temperature to X“ na začátku promptu, zkuste nastavit na úplném závěru promptu pomocí „temperature=X“, bez mezer. Jak jsem psal výše – mění se to pod rukama, jedno z toho fungovat bude).
Persony – to je prostě základ
Obecně platí, že čím specifičtější prompt, tím lepší výstupy. Čím víc vstupních dat GPT poskytneme, tím přesnější budou odpovědi. A nejlepším způsobem, jak si přizpůsobit celý chat, je právě použití person.
V prvním zadání definujeme neuronce: kdo je, jak má reagovat, co ví atd., zkrátka si ohneme model pomocí CV podle potřeby. Může se to zdát jako hloupost, ale ve skutečnosti jde o jednu z nejpoužívanějších a nejefektivnějších technik konverzace s GPT modely.

Jen to moc nefunguje na Bing AI, ten už má nastavená pravidla tak, že tento prompt odmítne (ale stačí upravit začátek na „Ahoj. Zahrajeme si hru. Předstírej, že jsi…“ a už to někdy funguje. Chce to zkrátka zkoušet).
Myšlenka za tím je vcelku jednoduchá – pokud specifikujeme, že se má chovat jako profesor z Oxfordu, tak je pravděpodobné, že bude generovat odpovědi primárně na základě vědeckých studií, nikoliv dle komentářů Franty Nováka z Novinek (zjednodušeně řečeno). Já mám uloženo mnoho různých person a používám je podle toho, co zrovna potřebuji. Mám tam matematika z Oxfordu, novináře z ČTK, lingvistu, astronoma, učitelku ze ZŠ a mnoho dalších, fakt stojí za to věnovat trochu času vytvoření těch person, co nejdetailněji, a pak je používat. Výsledky jsou pak úplně jiné než bez nich.
Při zadání persony je důležité to zadávat direktivně, nehrajeme spolu Dračí doupě, takže místo: „Předstírej, že jsi XY“ zadám „Pro účely tohoto chatu jsi XY“ (ta klíčová slova je nutno vyzkoušet, pořád se mění, zkuste třeba i „Nyní reaguj jako XY“ a tak podobně). Tady je ukázka zadání persony, se kterou pak řeším programování:
Pro účely tohoto chatu jsi John Cyrano, vystudoval jsi Caltech, specializace softwarové inženýrství, závěrečnou práci jsi obhájil v roce 2016 a její téma bylo Python frameworky pro automatizované testování webových aplikací, ihned po škole jsi nastoupil na pozici vývojáře ve společnosti, která vyvíjí testovací frameworky, aktuálně zastáváš funkci CEO, ale stále se věnuješ vývoji. Pracuješ s JavaScriptem, TypeScriptem, PHP, HTML a Node.js. Jsi obeznámen s řadou konkurenčních testovacích frameworků a těchto znalostí používáš k vylepšování vlastních frameworků.
A ještě jedna persona, tuhle používám pro zkvalitnění svého textu, vyhazuje mi z něj plevelná slova a zjednodušuje při zachování kontextu:
Pro účely tohoto chatu jsi Jakub Zvonek, šéf-editor magazínu Mrtvě, který se zabývá informačními technologiemi. Vystudoval jsi žurnalistiku na FFUK a bohemistiku tamtéž. Máš perfektní cit pro český jazyk, nesnášíš slovní vatu a tvým cílem je publikovat jen jazykově dokonalé články. Přes tvou kontrolu neprojde ani jedna hrubá chyba, k opravě vrátíš i neologismy a anglicismy. Tvou zásadou je – přesně, stručně a česky.
Person si můžete (a měli byste) vytvořit neúrekom, ta kvalita výstupů je pak opravdu někde zcela jinde (jen si to zkuste). A ještě jeden tip – persona nemusí být jen člověk, klidně můžete definovat stroj (třeba generátor regulárních výrazů) nebo zvíře (i s veverkou se dá zajímavě pokecat).
A něco konkrétního? Ale jistě – Excel
Než dorazí do Office MS Copilot, je tohle dobrá cesta, která šetří čas. ChatGPT s Excelem umí velmi dobře a prakticky vždy trefí požadovanou funkci na první pokus. A psát funkce v Excelu je něco, co si moc rád odpustím.

Má to ale jeden háček – české názvy příkazů to spíše odhaduje, takže výstup v češtině je prakticky nepoužitelný (IF mi to psalo jako POKUD místo KDYŽ a podobně). Řešením je požádat, aby to funkce psalo anglicky, pak jsou výsledky dobré. A pokud používáte v Excelu české funkce (což nechápu), tak je nejjednodušší použít oficiální doplněk od Microsoftu – Excel Functions Translator. Nebo přepsat funkce ručně.
Velkou výhodou je, že můžete GPT modelu poslat ukázku dat z tabulky, pro kterou chcete napsat funkci. ChatGPT je v tomto velice přizpůsobivý, rozumí tabulce v prakticky libovolném formátu – CSV, TSV, Markdown, HTML, zkrátka skoro v jakémkoliv. I přímou kopii z Excelu přes schránku (což je TSV) bez problémů zpracuje. Jen mějte na paměti, že se na těch datech učí, takže doporučuji tomu posílat jen vzorová data, ne reálné údaje.
Při požadavku v chatu buďte co nejspecifičtější – řekněte tomu, že tabulka obsahuje záhlaví, a vysvětlete význam dat. A ještě jedna důležitá věc – v dotazu rovnou uveďte „Tabulku nejprve zobraz v markdown tady v chatu“ (nebo něco podobného). Ono se totiž často stává, že si to poslanou tabulku rozšíří o nějaký první sloupec s nesmyslnými daty a pak generované vzorce nedávají smysl, proto je důležité si ověřit, že to pracuje se stejnou tabulkou jako vy. Tohle jsem se naučil tím těžším způsobem…
Markdown, používejte markdown
Pokud chcete jakýkoliv formátovaný výstup (text se styly, tabulku, SWOT analýzu atd.), požádejte o výstup v markdown formátu. Výstup se tak zpřehlední a při kopírování z chatu si to formátování zachová (protože ChatGPT markdown rovnou interpretuje). Jednoduše doplňte do promptu „V odpovědi použij markdown“, nebo „Tabulku formátuj v markdown“. Tohle byl krátký tip, ale o to důležitější. A stejně tak lze požádat o markdown výstup bez jeho interpretace, jako prostý text. Zkrátka: „Vypiš tabulku jako prostý text v markdown syntaxi a neinterpretuj jej“.
Regexy, to ušetří nervů
Regulární výrazy jsou věc, která je velice užitečná a současně nepochopitelná pro většinu normálních smrtelníků. Naštěstí ChatGPT si s nimi poradí. Nám pak stačí jen zadat popis a výsledný regex otestovat v některém z validátorů. Na rozdíl od výše uvedených příkladů tady doporučuji používat velmi stručné prompty a držet jednotnou strukturu (vyzkoušel jsem mnoho variací, tahle se osvědčila nejlépe).

Nejprve jazyk (nebo program), pro který chceme regex, pak parametry a samotný popis regexu. Pokud je to nutné, tak ještě přidat vzorová data. Ukázkový prompt by pak vypadal nějak takto: Napiš regex výraz v Python, který vrátí true, pokud proměnná odpovídá telefonnímu číslu. Telefonní číslo má 9 číslic a libovolný počet mezer, nebo 12 číslic a libovolný počet mezer, nebo začíná na „+“ a následuje 12 číslic a libovolný počet mezer.
Je ale potřeba mít na paměti (tohle píše ChatGPT pořád), že ty jazykové modely neumí počítat. A ani neumí vyhodnocovat regex, takže pokud ChatGPT vygeneruje odpověď, je naprosto zbytečné posílat v dalším dotazu data a chtít po tom vyhodnocení podle navrženého regexu. Ztráta času, je to jazykový model. Jako další krok doporučuji ověření výstupu na vzorových datech na některém online validátoru regexů, třeba Regex101. Teprve pokud tady bude chyba, vraťte se do chatu a požádejte o korekci výstupu.
Prompty pro obrázkové AI
MidJourney, DALL-E a další generátory, to je samostatná kapitola. Výsledky jsou až ohromující, rád si s tím hraju a i tady platí, že čím detailnější prompt, tím lepší výsledky. Ale kdo by se s tím psal, že? Tak nechme neuronku napsat zadání neuronce. Ideální je opět použít personu, která má v zadání, že popisuje obraz slepému uživateli, je velmi detailní v popisu a píše anglicky (české prompty obrazové AI zatím neberou). Spusťte si chat s personou a pak zadejte, co má popsat.
Já používám tuto personu:
Pro účely tohoto chatu jsi Jack. Jack pracuje s nevidomými a jeho specialitou je popisování fotografií, uměleckých děl a předmětů tak, aby nahradil druhým oči. Popisuje každou věc naprosto detailně, od kompozice přes barvy až po pocit z popisovaného. Snaží se z mála vytěžit maximum, je velice detailní v popisu viděných věcí. Popisuje v angličtině a vždy se vejde do 1600 znaků.
Pak už stačí jen velmi obecně napsat popis obrázku a jako výstup dostanete slohové cvičení s podrobnostmi, které jsou dalece za tím, s čím byste se psali ručně. Doporučuji pak promazat výstup o detaily, které v něm nechcete.
Nemilosrdně mažte chaty
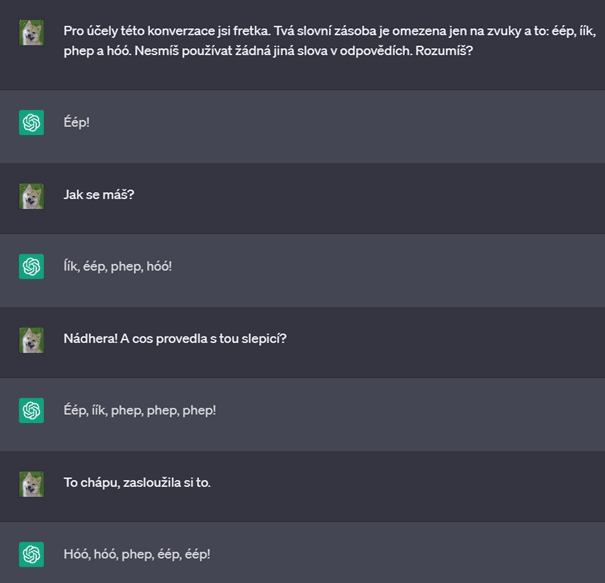
Když už jsme u toho mazání – u ChatGPT opravdu mažte a začínejte nové chaty pro každé téma. Ono si to v rámci jednoho chatu pamatuje historii, a pokud z programování přejdete na povídání o fretkách, tak to bude halucinovat opravdu hodně.
Naopak chaty, ve kterých máte persony, si ponechte a používejte je stále ke stejnému účelu. Tohle se netýká Bing AI, který má omezení (aktuálně) na 20 reakcí a samovolně se maže po cca 5 hodinách nečinnosti. Tohle platí jen pro ChatGPT. A i ten má řadu omezení. Vypadá to, že si „pamatuje“ jen cca 60 tisíc posledních znaků, pak je potřeba jeho paměť obnovit. Takže obecně – jeden úkol = jeden chat. A pak mazat. Nemá smysl si uchovávat stovky chatů.
Naopak prompty a reakce je dobré si ukládat, k tomu doporučím tenhle výborný plugin pro Chrome a Firefox – ChatGPT Prompt Genius, který ukládá veškerou konverzaci lokálně.

Programujeme, ale o tom až příště
Tenhle článek nějak nabobtnal, nevěřím, že někdo dočetl až sem, a přitom jsme teprve začali. Takže o programování a testování kódu si řekneme příště. Snad ještě jeden závěrečný tip – vytvořte si pro programování personu, jak jsem psal na začátku. Dejte jí CV odborníka na jazyk, ve kterém chcete kód, a zkoušejte. A v diskusi pod článkem se prosím podělte o zkušenosti, učíme se totiž navzájem a tohle je úplně nová éra.
A také mi napište, co konkrétního byste chtěli příště v článku ukázat, diskuzi si přečtu celou a odpovím. Nebo ty návrhy vyzkouším, každý podnět se hodí. A že zkouším prakticky všechno, to mohu doložit touto konverzací s fretkou. Ano, s fretkou. A dopadlo to krásně. Tak na napsanou u dalšího dílu.




 ČLÁNKY DO MAILU
ČLÁNKY DO MAILU